
Xpath Tutorial Part 1: A Practical Approach for Selenium Users
- March 14, 2014
- in Subject7
Intro
This article is for people who want to use Selenium and need to learn XPath. It is organized in several sections where each has a sample scenario and a sample XPath.
In general, we are not going to get too technical about creating a reference for XPath, instead the main focus will be the outline on how to get the XPath you need for Selenium Test Automation. You can find a reference at https://www.w3schools.com/xml/xpath_intro.asp
Getting Ready
You will need Chrome 68.x or above for this tutorial.
Install Chrome and launch it.
Here is how you would use Chrome to get to the XPath that you need:
Step 1: Launch a Chrome instances and browse to https://mail.yahoo.com. Then Right click on first box for email address
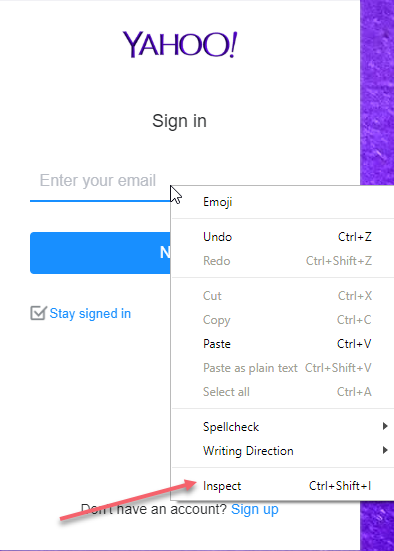
Step 2: Select “Inspect Element as shown above:
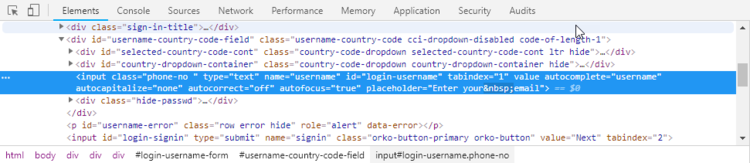
As you can see the input element with id=login-username is highlighted in blue. Pay attention to the selected tab in the newly opened window: Elements. There are also other tabs for different operations but for this tutorial you would only need Elements and Console tabs.
You can have the Chrome inspector embedded or open up as a separate pop-up whichever you prefer.
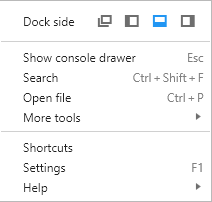
The leftmost button opens up Chrome inspector in a new popup or window, the second button embeds the inspector to the left of the browser, the third embds it at the bottom, and the rightmost embeds it to the right.
Step 3: Now tab over to Console.
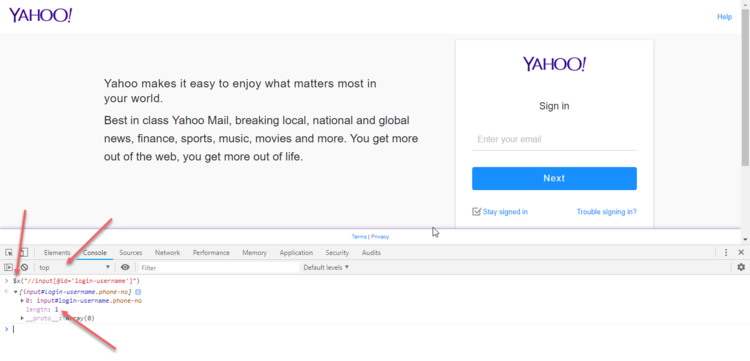
Chrome Console can be used to test an XPath before using it in Selenium. As shown on the image, the XPath has one match and the targeted element is highlighted if you hover on the returned result(s). Simply type $x(“”) in the console right after ‘>’ and include your XPath within the double quotes and hit enter, if you get a match you are set, if you do not, you need to revise your XPath expression. However, if you get more than one match then you have to make your selection stricter or specify which element you specifically want from the list. For example, if //input matches 5 nodes then (//input)[1] will give you the first one and (//input)[2] the second and so on.
The drop down underneath Elements which currently shows “top” indicates where the element is located in terms of frames.
You can use CTRL + L to clear out your console window.
Quick Review of XPath
In simple words, XPath is an expression used to locate html elements on screen. You can think of it as a query language to target elements on the page. Here are some basic examples:
| XPath Expression | Description |
| //input[@id=’username’] | Returns inputs with id=username |
| //input[@type=’text’] | Returns all inputs of type text |
| //table/tbody/tr[1] | Returns 1st rows of all tables on this page |
| //div | Returns all the divs on this page |
| //a[text()= ‘MyText’] | Returns a link that has the text matching precisely “MyText”. So MyText would be a match but MyText will not match because of extra spaces at the end. |
| //*[contains(text(),’hel’)] | Returns all elements that contain the text ‘hel’. Here are some possible matches: <div>hello</div> <tr> <td>hel </td></tr> <a href=”#”>Shell</a> |
Anything that comes immediately after // is an HTML tag or just use * as wildcard. Every web page is based on HTML code and it is called DOM (Document Object Model). In fact HTML is an XML document that browsers can render into the nicely looking web pages. XPath can be used to locate elements (Textbox, Links, Images, etc.) in an XML document.
Relative vs. Absolute XPath
An absolute XPath starts from the beginning of the DOM and follows the hierarchy of tags blindly until it reaches the target element. Absolute XPath expression starts with ‘/’. A relative XPath is much smarter and it can figure out the target element based on some hints and starts with ‘//’.
The problem with absolute XPath is that the smallest change to your webpage such as adding an element or changing positions will break your XPath.
To use XPath with Selenium you need to master a handful of techniques without diving too deep into the subject of XPath. This handful of techniques will cover more than 95% of all the XPath you need for your automation.
Ready to learn more about Subject7?
Archives
Recent Posts
- How Product Management Can Measure and Improve Product Quality
- Why Product Management Should be the Steward of Quality for Your Organization
- Wait, Is Avoiding Low-Code an Automation Anti-Pattern?
- DevOps and SecOps finally intersecting, what this means for your process
- Test Approaches and Types Distilled
